

工業企業原始+合并數據+dofile+日志(Brandt處理1998-2013年)
會員限領
| 來源:原始+dofile+結果
一、數據介紹
工業企業數據樣本大、指標多、時間長。是實證研究的一大利器,但其樣本存在匹配混亂、指標缺失、指標異常、測度誤差明顯、變量模糊等缺點(聶輝華,2012)。
在此之前,團隊整理的工企和海關、專利、污染數據的匹配,滿足了不少學者的需求。
但若將工業企業數據用于其他分析,仍是一項非常費時的工程。因此,團隊參照Brandt等(2012)針對中國工業企業數據庫提供的一套嚴謹的處理方法,對1998~2013年的工業企業數據進行了處理。
經過處理,最終得到非平衡面板數據400多萬條,平衡面板30多萬條。
內含原始、合并數據、dofile、運行日志,可直接用于研究。
二、處理方式
set more off
統一sdxm 省地縣碼,以得到省 地區 市等代碼
處理缺失變量
需要用到收入,但2004年以前的變量為產品銷售收入,2004年及以后為營業收入,因此需要統一 已經手動處理成zyrs
生成利潤這一變量用于匹配
保留用于匹配的變量和自己想要保存的變量
保存運算結果
將ID中的字母都變成大寫的
之前的都是為了運行brant代碼
運行brant代碼
設i為當年,j為下一年
Step 10 首先根據法人代碼(id)進行匹配,分離出id重復的樣本
保留ID重復的樣本
將重復樣本保存
將匹配成功的保存
處理下一年的數據,方法跟上面一樣
保存重復ID的樣本
保存匹配成功的樣本
為了方便后面的識別,需要將匹配成功的樣本生成匹配方法和匹配結果兩個變量(1為i年未匹配成功;2為j年未匹配成功;3為匹配成功)
相鄰兩年以ID匹配成功的樣本保存
Step 20 將未能用ID匹配成功的樣本以企業名稱進行匹配
保留i年未匹配成功樣本
合并ID重復的樣本
保存
Step 30 未能以企業名稱匹配成功的,再以法人(frdbxm)+地區碼(region_codedq)進行匹配,當然大家還可以修改為其他匹配變量,例如郵編、傳真等
Step 40 上兩步未匹配成功的再以電話(phone)+地區碼(dq)+行業代碼(hylb)進行匹配
Step 50 以上沒有匹配成功的再以開業年(bdat)+地區代碼(dq)+行業代碼(hylb)+鄉鎮(town)+產品1(product1)進行匹配
Step 60 將匹配成功的和未最終匹配成功的樣本重新合并成文件用于下一步的匹配
Step 70 創造一個三年的平衡樣本
Step 80 對未匹配成功的i年公司和j年公司單獨保存
Step 90 對i年公司和第三年k的公司以法人代碼(id)和公司名稱(name)進行匹配
step 100 將上述所有樣本再進行大合并
step 110 將2001從1999-2000-2001中加入 將2001年的數據合并進來
step 120 將2002從 2000-2001-2002中提取出來,加入
step 130 將 2003 從2001-2002-2003中提取出來,加入
step 140 將 2004從 2002-2003-2004中提取出來,加入
step 150 將2005從2003-2004-2005中提取出來,加入
step 160 將2006 從2004-2005-2006中提取出來,加入
step 170 將2007 從2005-2006-2007 提取出來,加入
step 180 將2008 從2006-2007-2008中提取出來,加入
step 190 將2009 從2007-2008-2009中提取出來,加入
step 200 將2010 從2008-2009-2010中提取出來,加入
step 210 將2011 從2009-2010-2011中提取出來,加入
step 220 將2012 從2010-2011-2012中提取出來,加入
step 230 將2012 從2011-2012-2013中提取出來,加入
生成非平衡面板數據文件
提取每年的樣本數
將各年樣本合并成面板數據
統一行業代碼
工業企業最終的平衡面板數據
三、數據概覽

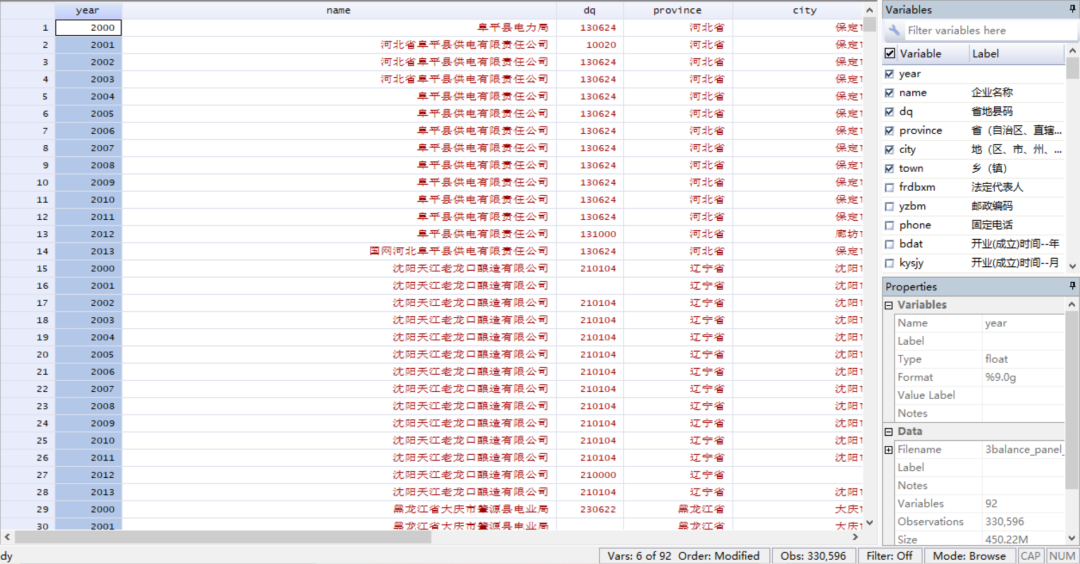
四、獲取數據
注:該數據為馬克社區高級會員-附贈數據
需要登錄后查看 點擊登錄

客服一:372574023(QQ)
客服二:
 macrodatas@163.com
macrodatas@163.com
macrodatas@163.com 
- Copyright 馬克數據網
- 渝ICP備2020011838號-1